GPT-5.5 Tops Academic Benchmarks but Loses to Rivals in Real-User Tests



For OpenAI, the release of GPT-5.5 a week ago was a big deal. For one thing, it is the first AI model in a long time to have received a complete pre-training — and it is meant to lay the foundation for everything else related to AI agents. In the benchmarks published by OpenAI, the new LLM naturally also shines in comparison to the two main competitors, Claude Opus 4.7 from Anthropic and Gemini 3.1 Pro from Google.
But what about independent tests? Here, a mixed picture is emerging. On Arena.ai, where users rate the outputs of AI models in a blind test, GPT-5.5 currently fails to surpass the LLMs from Anthropic (both Claude Opus 4.7 and 4.6), Gemini 3.1 Pro from Google, and — interestingly — Muse Spark from Meta.
Here is the current ranking:
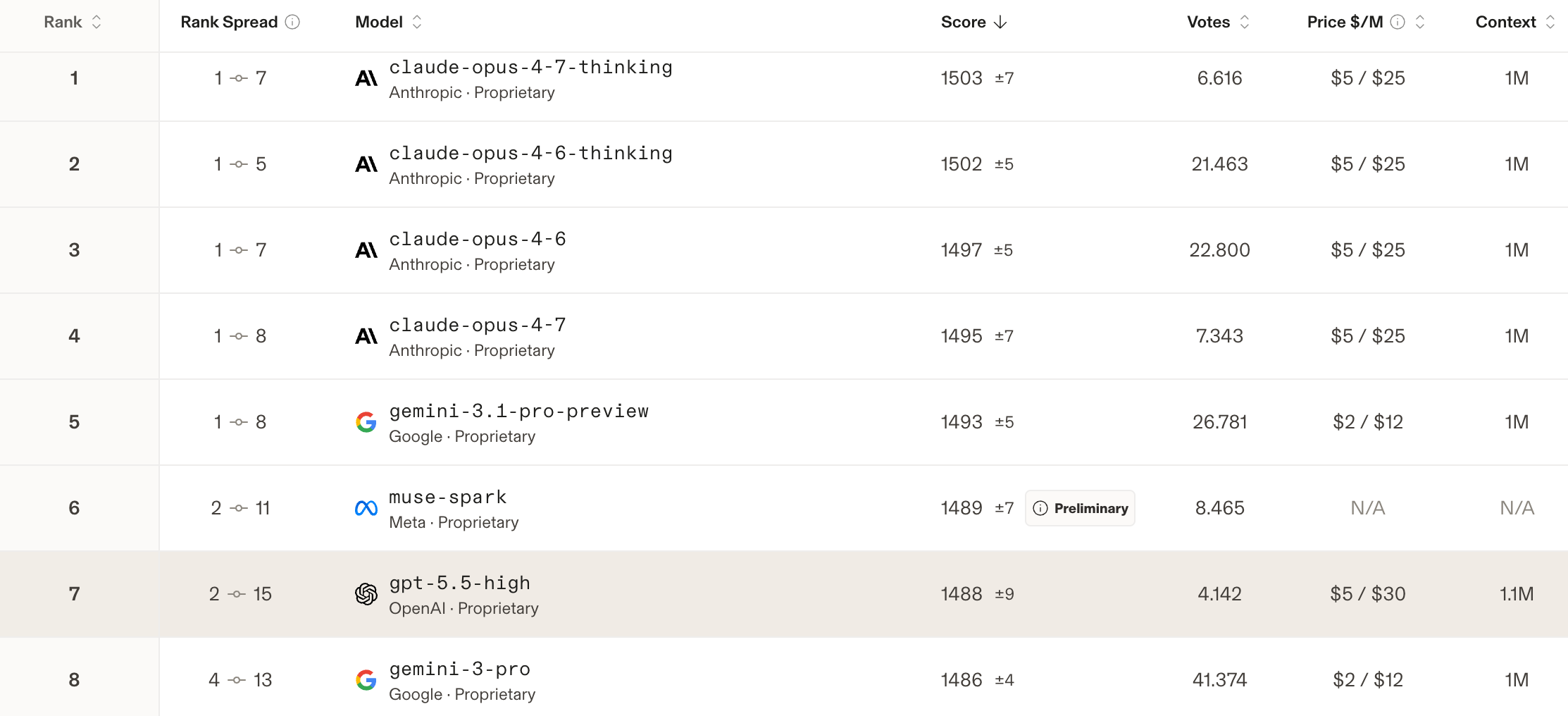
In contrast to the Artificial Analysis Intelligence Index, which evaluates AI models based on standardized academic tests, LMArena (arena.ai) takes a fundamentally different approach: here, real user preferences determine the ranking. On the platform, users enter any prompt and receive responses from two anonymous AI models in parallel. They select the answer they consider better, without knowing which model is behind it — only after voting are the names revealed. From millions of such blind duels, LMArena uses the Bradley-Terry model — a further development of the ELO system known from chess — to calculate a continuously updated leaderboard.
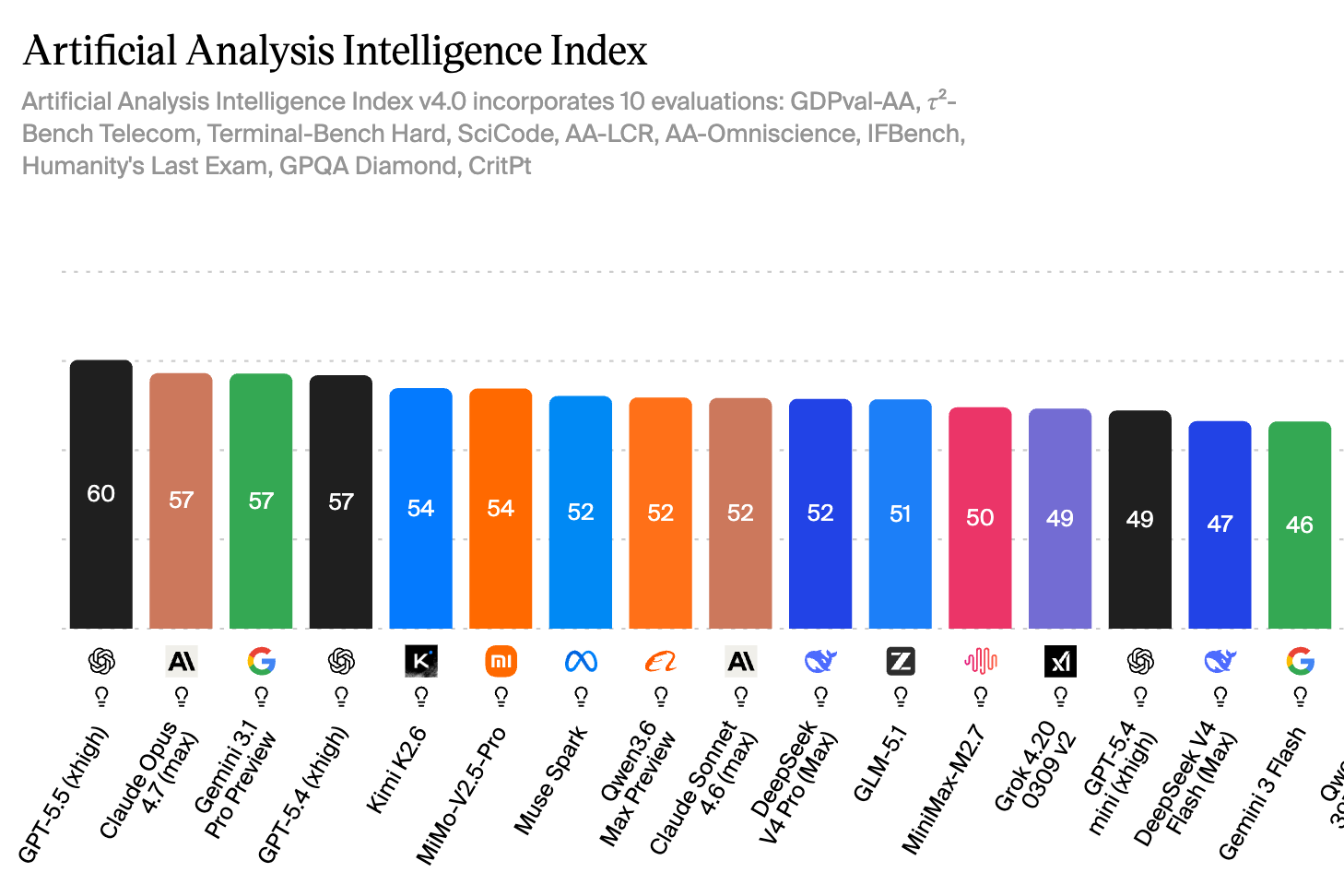
Top Results at Artificial Analysis
At Artificial Analysis, on the other hand, GPT-5.5 (in the “xhigh” version) currently ranks 1st, ahead of Claude Opus 4.7 and Gemini 3.1 Pro. The difference in measurement compared to Arena.ai: while users do the rating there, Artificial Analysis combines ten different tests, each examining different capabilities — broadly grouped into four categories:
- Logical reasoning & inference (e.g. Humanity’s Last Exam, GPQA Diamond)
- Knowledge (e.g. AA-Omniscience, AA-LCR)
- Mathematics & science (e.g. SciCode, CritPt)
- Coding & practical tasks (e.g. Terminal-Bench Hard, GDPval-AA, 𝜏²-Bench Telecom, IFBench)
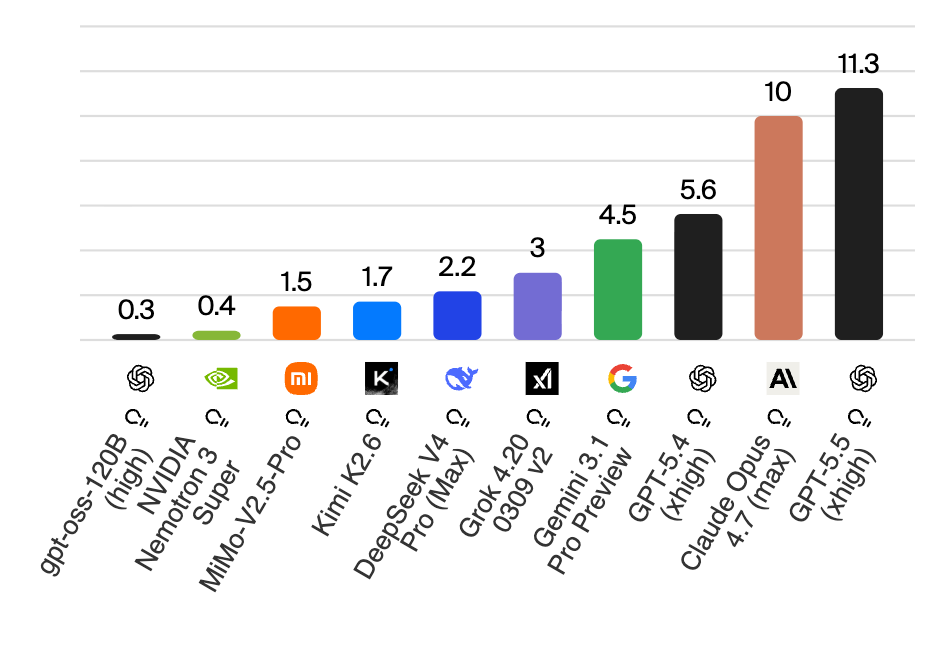
More Expensive Than the Competition
What also comes with the increased performance is a higher price. “GPT-5.5 (High) is among the leading models in terms of intelligence, but is particularly expensive compared to other models in the same price range,” states Artificial Analysis. Here is the comparison with the in-house alternatives:
| Model | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
| GPT-5.4 | $2.50 | $15.00 |
| GPT-5.5 | $5.00 | $30.00 |
| GPT-5.5 Pro | $30.00 | $180.00 |
Compared to the AI models of its competitors, OpenAI is now the most expensive with GPT-5.5: