OLMo: „Wirklich offenes“ AI-Modell kommt mitsamt den Trainingsdaten



Kenner:innen der AI-Branche sehen den Seitenhieb gegen OpenAI, Meta und Google sofort: Das Allen Institute for AI (kurz AI2) hat mit OLMo ein neues Large Language Model (LLM) an den Start gebracht, das mit einem neuen Open-Source-Ansatz die neu definieren soll, was „Open AI“ wirklich bedeuten kann. Denn OLMo, das man als geneigter Developers via Hugging Face und GitHub beziehen kann, kommt mit den kompletten Trainingsdaten daher.
Wie bekannt ist, sind die Trainingsdaten für AI-Modelle – von GPT-4 bis OLMo – eine essenzielle Sache und nicht nur für die Qualität des LLMs wichtig, sondern auch Gegenstand mittlerweile zahlreicher Rechtsstreits. AI1, die 2014 von Microsoft-Mitgründer Paul Allen ins Leben gerufene Non-Profit-Organisation, will dem aus dem Weg gehen und liefert mit OLMo gleich vollständige Pretraining-Daten mit. „Das Modell basiert auf dem Dolma-Set von AI2, das ein offenes Korpus mit drei Billionen Token für das Vortraining des Sprachmodells enthält, einschließlich des Codes, der die Trainingsdaten erzeugt“m heißt es seitens AI2.
OLMo auf ähnlichem Level wie Llama 2 von Meta
Außerdem umfasse das OLMo-Framework zusätzlich „vollständige Modellgewichte für vier Modellvarianten auf der 7B-Skala, die jeweils mit mindestens 2T Token trainiert wurden“. Inferenzcode, Trainingsmetriken und Trainingsprotokolle würden ebenfalls bereitgestellt. Außerdem können Entwickler:innen, die OLMo einsetzen möchten, quasi in der Entwicklungszeit zurückgehen, weil mehr als 500 Kontrollpunkte pro Modell aus allen 1.000 Schritten während des Trainingsprozesses veröffentlicht werden. So könnte man auf ältere Versionen zurücksetzen, sollten sich Fehler einschleichen.
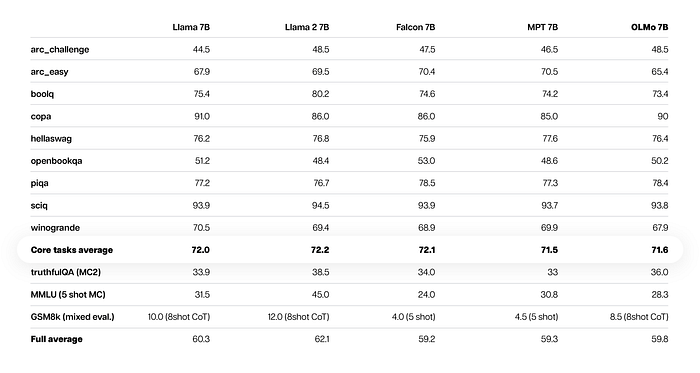
Wie gut ist OLMo aber nun? Vergleiche zu den aktuell stärksten AI-Modellen wie GPT-4 von OpenAI, Gemini 1.5 von Google oder Claude 3 von Anthropic werden gar nicht erst gezogen. Stattdessen wurde OLMo 7B in Benchmark-Tests mit anderen Open-Source-Modellen verglichen, darunter Falcon 7B des Technology Innovation Institute (TII) aus den Vereinigten Arabischen Emiraten, MPT 7B (ein etwa ein Jahr altes Modell von MosaicML) sowie Llama 2 von Meta verglichen. Llama 2 ist vermutlich in einer Woche bereits ein alter Hut, weil Meta aktuell den Launch von Llama 3 vorbereiten soll.
„Viele Sprachmodelle werden heute mit begrenzter Transparenz veröffentlicht. Ohne Zugang zu den Trainingsdaten können die Forscher nicht wissenschaftlich nachvollziehen, wie ein Modell funktioniert. Das ist vergleichbar mit der Entdeckung von Medikamenten ohne klinische Studien oder der Untersuchung des Sonnensystems ohne Teleskop“, so Hanna Hajishirzi, Leiterin des OLMo-Projekts. „Mit unserem neuen Rahmenwerk werden Forscher:innen endlich in der Lage sein, die Wissenschaft der LLMs zu studieren, was für die Entwicklung der nächsten Generation sicherer und vertrauenswürdiger KI entscheidend ist.“
Gerechnet wurde OLMo übrigens mit dem LUMI-Supercomputer in Finnland. Dabei handelt es sich um eines der europäischen High-Performance Computing (EuroHPC) Projekte, es ist der drittgrößte Supercomputer der Welt und der größte in Europa. Auch das finnische AI-Startup Silo AI arbeitet mit LUMI. AI2 hat mit Meta, Microsoft und Databricks (Mutter von MosaicML) eine Reihe von Unternehmen als Partner, die allesamt selbst an LLMs arbeiten.
























